
1��16�գ�AI֪ʶ���ܼ�������������AI�ٰ����켼�������գ�Zhipu DevDay����ȫ��չʾ����Ͷ����ģ����ҵ��������������۵ļ����ɹ�������������һ��������ģ��GLM-4��
����AI CEO������ʾ��GLM-4���������������һ������������ƽ�GPT-4������֧�ָ����������ģ��߱���ǿ�Ķ�ģ̬������ͬʱ��GLM-4�������ٶȸ��죬֧�ָ��ߵIJ�������������ɱ���

ͼԴ������AI
����֮�⣬GLM-4���������������������GLM-4 All Toolsʵ�����������û���ͼ���Զ����⡢�滮����ָ����ɵ�����ҳ�������Code Interpreter����������Ͷ�ģ̬����ͼ��ģ������ɸ�������GLMs���Ի������嶨�ƹ�����ͬʱ���ߣ��û��ü���ʾ��ָ����ܴ��������Լ���GLM�����壬��������˴�ģ��ʹ���ż���
����OpenAI�����Ա�Open AI������AI����������Ŀ�ꡱ���������ڶ������ʱ�Ŵ��ἰ�ļ��仰��Ŀǰ��ģ�͵ľ����Ѿ������Ǵ�0��1��������֮�����������֮�������Ҵ�ģ�Ϳ�ʼ�����ⲫ������Ϊ���й�OpenAI��������AI�������ܷ��ڴ�ģ�ͽ���ս��˳��ͻΧ��
һ����ʱ���ԶԱ�OpenAI
����AI��Ϊ���ڵ�һ��Դ��ģ�ͣ����Ž�ǿ�ļ����ܹ������Ա�OpenAI����һЩ���롣
����̹�ԣ������ģ����ȣ����ڵĴ�ģ�ͷ�չ������һЩ�����ϸ������������ơ����������IJ��ȣ����ڴ�ģ���ڹ�ģ�ͺ��������϶��������Ƚ�ˮƽ����һ����࣬�����IJ���Լ��һ�����ҡ�
�Ӽ���·��������OpenAI�����ע��ͨ���ԡ�����ֲ�ԺͿ���չ�ԣ���GPTϵ��ģ�Ϳ����ڶ��������Ӧ�ã����Ҿ��и߶ȵĿɶ����ԡ����֮�£�����AI�ļ���·���ǡ���ģ��+Сģ�͡���ͨ����ģ�͵�Ԥѵ������������Ӧ��ͬ������������������ּ���·�߿������ģ�͵ķ���������Ӧ�÷�Χ����Ҳ������ģ���Ӷȸߡ���������ѵ��ʱ�䳤�����⡣
��ģ��ģ��OpenAI��GPTϵ��ģ��ģ�ϴ��Դ�����������Ȼ�������ݣ��Ӷ���ø��õ�ģ�����ܡ����֮�£�����AI��ģ��ģ���ܽ�С���������ݵ��������ޣ�����ܻ�Ӱ����ģ�����ܺͷ�������������������Դ���棬OpenAIӵ�д�������Ȼ����������Դ����������ѵ�����Ż���ģ�͡����֮�£�����AI��������Դ������Խ��٣�������ģ��ѵ����Ч���������ܵ����ơ�
����ζ�ţ���Ҫ�����ֲ���OpenAI֮��IJ�࣬����AI����Ҫ����������ģ��������ѵ��������ȻҲ��Ҫ��������Ӳ�ҵ���һ���ǣ�����AI���ʽ���Ҳ��������һ��������⡣
���ȣ�Ӳ����һ�ʾ�Ͷ�룬���������г��о�����TrendForce���㣬����ChatGPT��ѵ��������Ҫ2��öGPUоƬ��������OpenAI��һ��չ��ChatGPT������GPTģ�͵���ҵӦ�ã���GPU��������ͻ��3���ţ��ñ��������A100оƬΪ������
���⣬ѵ����ģ�͵ijɱ�Ҳ����С����ݹ�ʢ֤ȯ�����ġ�ChatGPT��Ҫ�������������㣬GPT-3ѵ��һ�εijɱ�ԼΪ140����Ԫ������һЩ�����LLM(��������ģ��)��ѵ���ɱ�����200����Ԫ��1200����Ԫ֮�䡣
���ʽ�����������Լ��ܻ��ض��ټ�ֵ����������AI������һ��δ֪����
��������������AI����Ͷ�ʻ���������2023��10�£�����AI�������ѳɹ����ʳ���25������ҡ���һ��Ҫ��������̱��õ��˶��֪�������Ļ���֧�֣���Ҫ���뷽�����籣�����йش��������»����Լ����š����ϡ������Ѷ��С�ס���ɽ��˳Ϊ�ʱ���BossֱƸ����δ������ɼ����겵ȶ�һ�����ͬʱҲ����һЩ�Ϲɶ��ĸ�Ͷ��
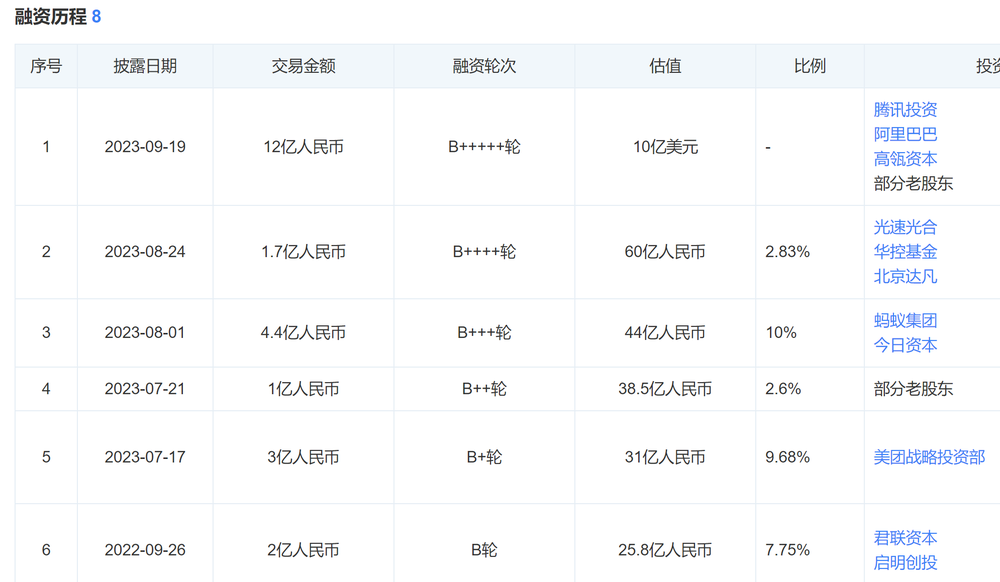
ͼԴ�����۲�
������2023����������AI��������5�����ʣ���ֵ����100��Ԫ����������AI�������ޡ���ҵ������AI��ʾ�����ʽ������ڽ�һ���ƶ��������ģ�͵��з����Ը��õ�֧�ֹ㷺����ҵ��̬���ٽ���������һ��ʵ�ָ���������Ը����
������ҵ����ǽ��Խ
��ҵ���������֤һ���¼�����ֵ����ֱ�ӵķ�ʽ���ֽ����������ڴ�ģ�Ͱٻ���ţ������Դ��ڽ�����������չ�ĽΣ�������ҵ����أ������ϴ���̽���Ρ�
������ԣ���ģ����ҵ��ӯ����ʽ��Ҫ������ģ�͡���ģ��+��������ģ��+Ӧ�á����У���ģ�ͺʹ�ģ��+����Ϊ��Ҫӯ����ʽ��
����AIӯ����ʽ����ҵӯ����ʽ����һ�£�һ�Ǹ��ݿͻ������ṩ��ģ�Ͷ��ƻ����������ƶ�˽�л�����˽�л���۸�ֱ�Ϊ120��Ԫ/���3690��Ԫ/�ꣻ���DZ����ģ�ͣ��ṩAPI���뷽ʽ������Tokensʹ���շѣ�ChatGLM-Turbo��CharacterGLM��Text-Embedding�շѱ��ֱ�Ϊ0.005Ԫ/ǧTokens��0.015Ԫ/ǧTokens��0.005Ԫ/ǧTokens��Ŀǰ������AI����ҵ����Ҫ������ҵ�ͻ�����B���û���
��Ϊ�Աȣ�OpenAI����ҵ��ͬ����ΪC�˺�B���������֣�������ԣ����C���г���OpenAI�Ƴ�ChatGPT Plus���ļƻ���ÿ���շ�20��Ԫ���������Ѱ汾�������ڸ߷�ʱ���û�Ҳ����������ChatGPT����Ӧʱ����죬���ҿ�������ʹ���¹��ܵȡ������B���г���OpenAI������ChatGPT API�������߿��Խ�ChatGPT���ɵ���Ʒ�У��Ը��Ӹ�Ч�ط��ӳ���ֵ��
ֵ��ע����ǣ�OpenAI����2023��8���Ƴ�����ҵ����棬�÷��������ÿ�¸�OpenAI����6500��Ԫ�����롣����2023�꣬OpenAI�Ƴ��Ķ���ѷ����Ѿ������˳���110��Ԫ�����롣
һ���ձ���������ڣ���������AI���ڵĹ��ڴ�ģ�Ͳ�Ʒ���ڸ�Ͷ���ͬʱ�����Դ����ȶ���ӯ������Ȼ��ģ����ҵ��֮·�����ҳ�����������֡�������2023����걨��ʾ����360���ԡ���ģ���Ѿ���ʼ���գ�����2000��Ԫ����������Ҳ����������ʽAI��2023���ϰ��������������670%��
��������ر���ָ����Ŀǰ��ģ����ҵ�����ٽϿ����ҵΪ��Դ�ͽ��ڣ���ԭ��������������ҵ�ܼ��ֲ����������������ݻ�����ʩ�����걸������Ͷ��ߡ�AIӦ�ó������һ���ǿ����Щԭ��ٽ���������ģ�͵Ŀ����ںϡ�
��������AI���ԣ�Ŀǰ��ģ����ҵ����·���Ѿ���Ϊ���������ܷ���ͨ��ģ�͵���ҵ��֮·���ؼ�����������ҵģʽ��̽�����ԣ������ڽ����ģ�ͷ�չ�ĵײ����⡣
����������ģ�ͺ�ȥ�δӣ�
���ݹ��Ų������о�Ժ�������ݣ�2023���ҹ����Դ�ģ���г���ģʵ�ֽϿ�������Ӧ�ó������Ϸḻ��Ԥ��2023���ҹ���ģ���г���ģ���ﵽ132.3��Ԫ�������ʽ���110%��
δ�������ż����IJ��ϵ�����������ģ�ͽ��ھ������ܡ��Զ���ʻ���������µ�Ӧ�ó�����
������ԣ���ģ�͵ķ�չ�����������ƣ������Ǵ�ģ������������������δ����ģ�ͽ����и��ߵľ��ȡ���ǿ�������������㷺�������ԣ�����ζ�Ŵ�ģ���ܹ����õ�������Ȼ���ԣ����ܹ����и���ĸ���������ȫ����ơ������ȵȣ�����Ǵ�ģ�ͽ�Ӧ���ڸ��������˴�ͳ���ı�����֮�⣬��ģ��Ҳ��������ʶ��ͼ�����ɡ���Ƶ����ȷ��淢�Ӹ�������ã��û������ڸ���ij��������ܵ�AI�����ı��������⣬��ģ�ͽ����Ӷ��ƻ����ܹ����õ������û��ĸ��Ի������û����Ը����Լ���ʵ������ѡ����ʵ�ģ�ͣ������ж��ƻ����á�
��ģ�ͷ��ٷ�չ����������ζ������չ��δ������Դ�ģ�͵ļ�ܽ������ϸ�2023��7�£����Ű���߲��ŷ����ˡ�����ʽ�˹����ܷ������й����취������ȷ�涨��ģ�Ͳ�Ʒ��ע��������˽��ȫ�����ܷǷ���ȡ����¶�����ø�����Ϣ����˽����ҵ���ܣ������ַ�֪ʶ��Ȩ����ģ�����ɵ�����Ӧ���������������ļ�ֵ�ۣ��������������Ե����ݵȵȡ�
���ڴ�ģ�͵�δ���������Ե�ʮ���ֹۣ���2024�꣬��ģ���г�����Ұ�������ع��侲�����ڴ�ģ�͵�Ͷ���보�������һ���䣬��ҵ����Ҳ����ģ�ͱ���ת��Ѱ��Ӧ�á������Ⲣ��������ģ�͵ļ����ݽ��ٶȻ��½�������̽�����컨�廹ԶԶû������

























